» Download this section as PDF (opens in a new tab/window)
There is a growing need for infrastructure that can span across edge, core, and/or the public cloud. For example, data can be generated and processed locally at several far-edge nodes, then sent back to the core datacenter for aggregate decision-making and fine-tuning the model.
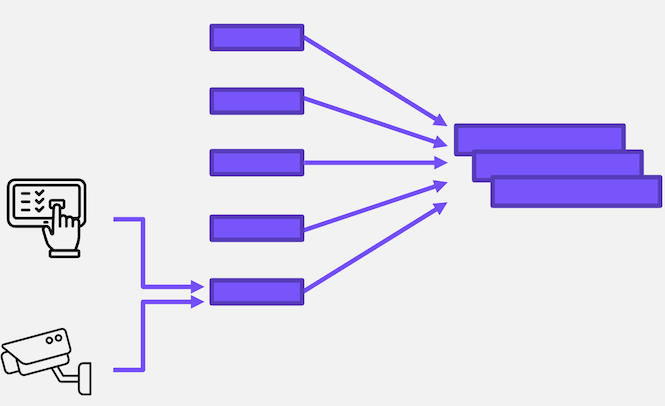
Regardless of what is deployed, you need a consistent operating model across the tiers. Nutanix Cloud Platform can run at all locations - whether it’s a single-node edge device, a multi-node cluster in your core datacenter, or in the public cloud with NC2. This provides a unified cloud operating model that enables the simple, consistent operation of your AI/ML platform.
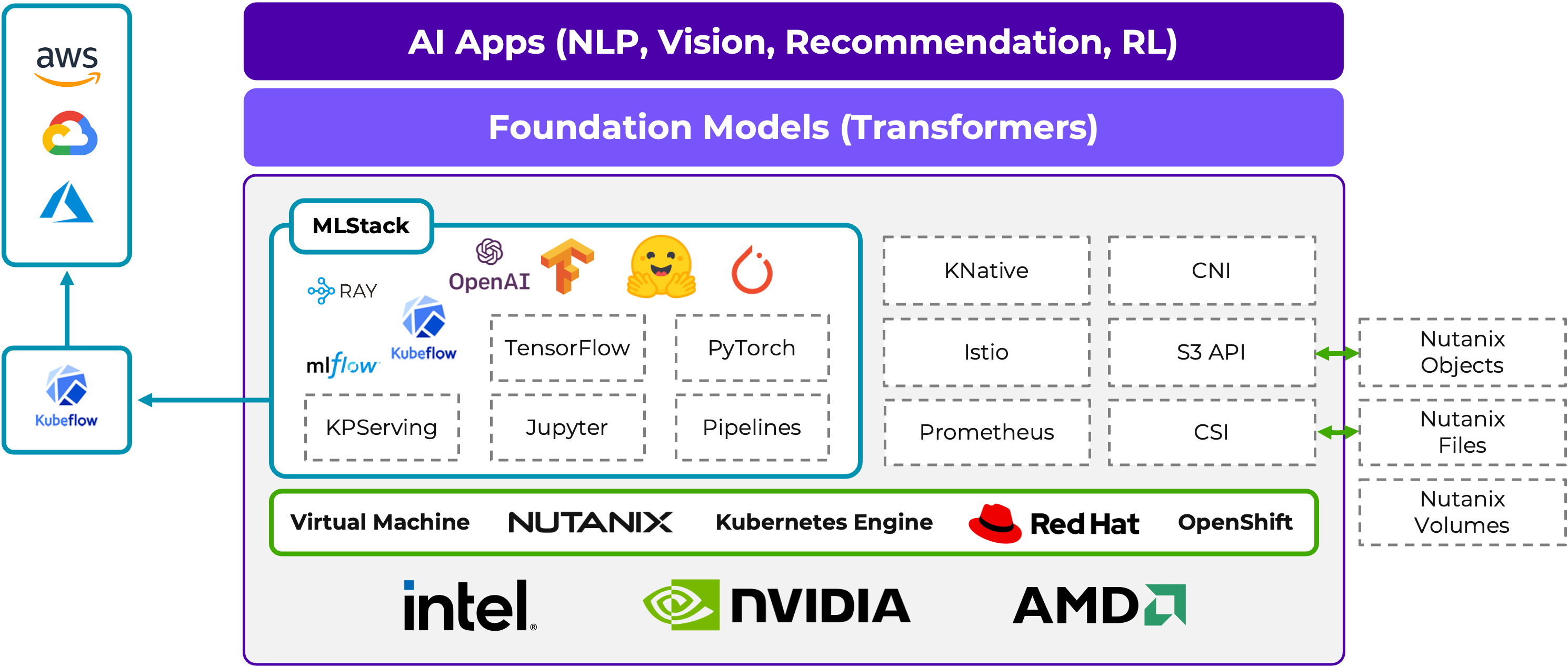
NCP supports a variety of hardware and NVIDIA GPU cards, and you can run your workloads on Nutanix Kubernetes Engine, Red Hat Openshift, or on VMs.
A key aspect of running AI/ML workloads is managing the machine learning lifecycle. The term MLOps is a compound of Machine Learning and Operations, and is analogous to DevOps, in that it aims to automate, orchestrate, and deploy models in a consistent and efficient manner. Kubeflow is a popular solution for MLOps, and the Nutanix Cloud Platform is validated for Kubeflow, enabling consistent MLOps across the tiers.
For more information on running AI/ML on Nutanix, check out the following resources:
©2025 Nutanix, Inc. All rights reserved. Nutanix, the Nutanix logo and all Nutanix product and service names mentioned are registered trademarks or trademarks of Nutanix, Inc. in the United States and other countries. All other brand names mentioned are for identification purposes only and may be the trademarks of their respective holder(s).